A fun administration programming challenge.
February 10, 2025

Summary
The goal of this post is to show how you can turn something not too interesting (administration) into a fun, educative, and useful programming exercise. Dependent on your Python experience you might also enjoy some of the code snippets, and I will show how you can select and extract any element on a webpage with just a few lines of JavaScript.
The challenge
As a freelancer I am obligated to have an invoice of all my business expenses. Every quarter, I upload these invoices to an accounting system which calculates how much value added tax I have to pay to the tax authorities. To prevent administration overload at the end of each quarter, I tend to regularly upload invoices during the quarter. Although this saves time at the end of the quarter, it also provides an additional challenge.
The challenge comes solely from the inflexible accounting software, which looks as follows.
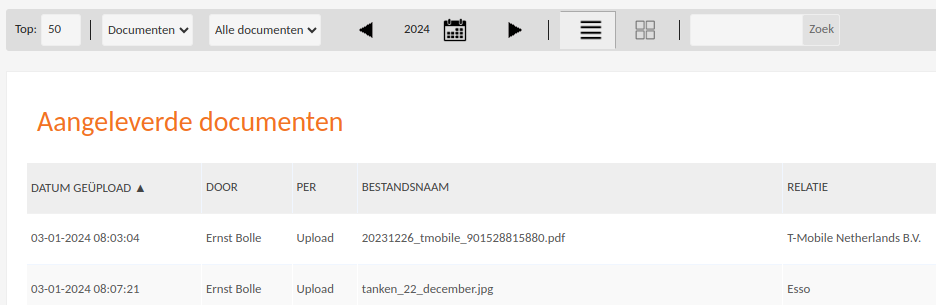
The software supports simple search and sorting functionality, but that is about it. It is not possible to download the overview.
The invoices that I need to upload to the accounting system are stored in a (local) folder with the following structure.
invoices/
├── 2024/
│ └── jan/
│ ├── insurance_invoice_123.pdf
│ └── mobile_phone_invoice_456.pdf
│ └── feb/
│ ├── accounting_invoice_789.pdf
│ └── 20240205_amazon_transformers_book.pdf
...
Since I do not want to get into any issues with the tax authorities, it is critical that every invoice is uploaded to the accounting system. We can assume that every invoice of every business transaction is in the local folder, but how do we make sure that we did not forget to upload all the files?
Well here is a solution for you!
Now before we are going to look at some fun programming stuff, I realize that there are many (easier) solutions to this problem. For starters, I could just reupload every invoice and let the deduplication be handled by the software or the accountants. This would work, but … where is the fun in that?
Break the challenge down into smaller pieces and start with the end
Over the years of teaching SQL to students with minimal programming experience, I have learned that it helps to ask questions that focus on the result of their query.
- How will the result look like?
- How many rows do you expect?
- How many columns?
- Why?
When they made the connection that the SELECT operator controls the number of columns, and the WHERE operator the number of rows, it
becomes easier for the students to write the query that brings them the intended result. Let’s apply the same method here.
The way I see it we end up with two sets of names of invoices. One set originates from the local folder, and the other set originates from the webpage of the accounting system. The result I am looking for are two empty sets.
set(invoices_in_local_folder).difference(set(invoices_in_accounting_system))
set()
set(invoices_in_accounting_system).difference(set(invoices_in_local_folder))
set()
Given the result we can divide the challenge into two sections: the local list of invoices and the accounting system list of invoices. Let’s start with the local list.
Extract the names of the invoices of the local list
First, we need to get access to the local folder structure and list all the files. There are many ways to do this but I prefer the Python build-in pathlib library and the
versatile Path object.
from pathlib import Path
invoices_2024_folder = Path(".") / "invoices" / "2024"
# list the files
[file for file in invoices_2024_folder.iterdir()]
The iterdir method returns a generator, and by wrapping the generator in a list comprehension we get the full result.
[PosixPath('../2024/maart'),
PosixPath('../2024/april'),
PosixPath('../2024/juni'),
PosixPath('../2024/oktober'),
PosixPath('../2024/mei'),
PosixPath('../2024/januari'),
PosixPath('../2024/augustus'),
PosixPath('../2024/februari'),
PosixPath('../2024/september'),
PosixPath('../2024/juli')]
Next, we need to filter the relevant directories for the third quarter. The name attribute holds the final path component, which is exacty what we want to filter on.
q3_paths = [file for file in facturen_path.iterdir() if file.name in ["juli", "augustus", "september"]]
To actually see the files that are located in the Q3 folders we need to iterate over these folder paths, for example:
[file for file in q3_paths[0].iterdir()]
[PosixPath('../2024/augustus/20141937-bolle-data-consultancy.pdf'),
PosixPath('../2024/augustus/Coolblue_factuur_1542362204.pdf'),
PosixPath('../2024/augustus/factuur_amazon_boek_transformers.pdf'),
PosixPath('../2024/augustus/factuur_open_universiteit_logica_relaties.PDF')]
Similar to the filtering action, we will leverage the name attribute to retrieve the list of names of the invoices. I have used the += operator to ‘add’ the lists,
which results in a single list of all the invoices instead of a list of lists.
local_files = []
for month in q3_paths:
all_files += [file.name for file in (month.iterdir())]
sorted(local_files)
Extract the names of the invoices of the accounting system webpage
Let’s have another look at the accounting system overview.
Since it is not possible to download the overview, we need to find another way to get the data out of the web page. Although I am not a web developer, I gained quite some web development experience building several websites from scratch, including this one. If you do not have any web development experience, the takeaway of this section is that you can select and manipulate every element on a webpage.
In our case, we are interested in the table area of the webpage. You can inspect this area (right click -> inspect) which will open the developer tools, and show you the underlying HTML structure of the webpage.
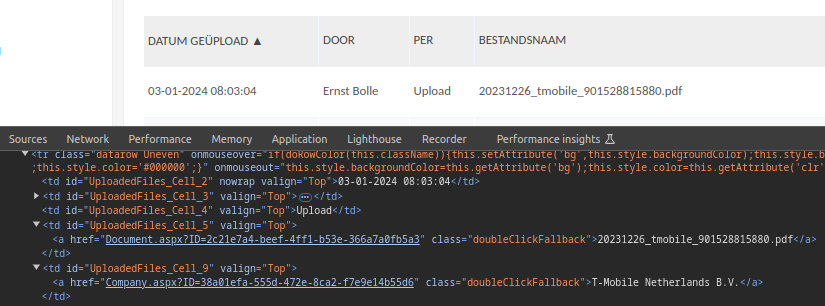
Tables on webpages typically make use of the ‘table’ HTML elements, such as td (table data cell element) and tr, which is the table row element.
The table data cell elements that we are interested in all seem to have an id of the format "UploadedFiles_Cell_x", and we can use that id to search and select
the data we want. Within the developer tools there is a “console” tab which allows to communicate with the page directly via JavaScript.
const allCells = document.querySelectorAll('[id^="UploadedFiles_Cell_"]');
The querySelectorAll method returns a NodeList with every element that adheres to the id pattern. I strongly encourage you to go to a webpage now and see if
you can select some elements yourself. When you do, open a single node, and be amazed by the sheer number of attributes and methods every node has. The attribute that
we are interested in is innerText.
const data = Array.from(allCells).map((cell) => cell.innerText);
The map method iterates over every element in the NodeList, and stores the innerText attribute. The Array.from functionality stores this data in an array, which
looks as follows:

To finish this section we need to to extract the array and import it into Python.
const jsonData = JSON.stringify(data, null, 2);
The value of 2 for the third argument ensures that the JSON is pretty printed with an indentation of 2 spaces. To keep things simple
I simply copy the data by right clicking and “copy as JSON literal” and paste it into a Python notebook.
import json
data = json.loads("[\n \"01-10-2024 19:27:25\",\n \"Ernst Bolle\",\n \"Upload\",\n ...]")
Although we now have all the data from the webpage available, we lost the structure of the table since we only extracted the data cells. Before comparing the list of names of invoices, we need to re-build the table in Python from the JSON literal.
Bring back the structure
The data variable is simply a list of all the data cell elements.
['01-10-2024 19:27:25',
'Ernst Bolle',
'Upload',
'Coolblue_factuur_1542362204.pdf',
'Coolblue B.V.',
'Verkoop\\Facturen',
'Afgehandeld',
'01-10-2024 19:20:39',
'Ernst Bolle',
'Upload',
'factuur_open_universiteit_logica_relaties.pdf',
'OpenUniversiteit',
'Verkoop\\facturen',
'Open',
'01-10-2024 19:20:39']
Although we lost the table structure, we can easily rebuild it since the data ‘repeats’ itself every seven elements. To create a dataframe from this list, I opted to create a list of lists, where each list represents a row in the webpage table.
accounting_system = pd.DataFrame([data[x:x+7] for x in list(range(0, 350, 7))])
accounting_system.columns = ["datum_geupload", "door", "per", "bestandsnaam", "relatie", "ordner", "status"]

Now that we have both the invoices from the local folder and the accounting system, it’s time to compare.
Compare the two lists of invoices
To make sure we compare the right invoices we need to filter the webpage data on invoices that are uploaded in the third quarter.
# the filter is accurate as long as I upload all my invoices *within* the quarter
accounting_system_files = accounting_system.loc[accounting_system["datum_geupload"] >= datetime.datetime(2024, 7, 1)]
set(local_files).difference(set(accounting_system["bestandsnaam"]))
set()
set(accounting_system["bestandsnaam"]).difference(set(local_files))
set()
Hopefully you enjoyed the read, I suspect more administration posts will come up since they are ideal candidates for fun and useful programming tasks.