Implementing a data-driven mindset by optimising the customer support department.
Summary
Due to its green energy success formula this e-mobility company grew faster than it could hire data-savvy and customer support colleagues.
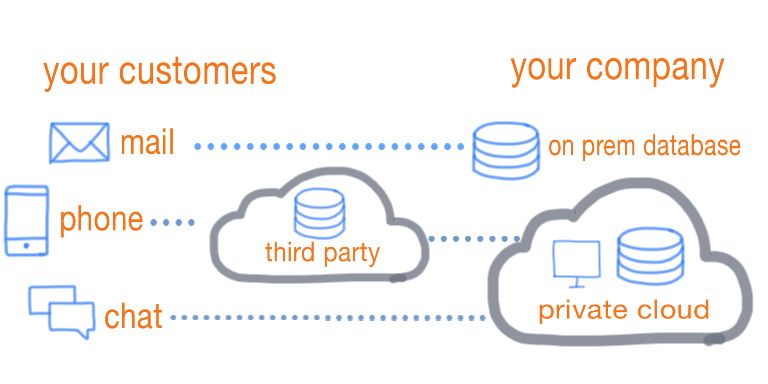
As the customerbase kept growing, the customer support team could no longer keep up with customer inquiries. Consequently, customers got frustrated since waiting times increased. The data generated by a third-party customer support service platform wasn’t used, so the customer support team had no idea why and when customers where reaching out.
The solution was simple yet effective. First, the third-party solution data was pulled into the private (Azure) cloud. Next, we enriched the data with two questions which we integrated in the working environment of the customer support agents.
- What was the main reason of the call?
- Were you able to solve the problem?
With the enriched data we could pinpoint the main drivers of the inquiries, and come up with a detailed action plan to reduce the number of inquiries, for example:
- Notify the B2B customers that they have their own dedicated customer support line.
- Moved the “which subscription should I choose?” helper tool to the hero spot on the homepage.
- Extended the FAQ and made it easier to find.
- Added detailed information of the app in the welcome email for new customers.
As a result, we significantly improved the customer journey of multiple communication channels.
My role and responsibilities
Since the company was at the beginning of their data-driven journey, my most important responsibility as a data scientist / project lead was to guide, explain, and show how data could help their workflow, and ultimately benefit their customers.
An interesting technical challenge was to securely pull the third-party solution data into their Azure Synapse Analytics environment.
Besides data analysis we used the Synapse environment to build and execute data pipelines with the Integrate functionality, which closely resembles Azure Data Factory. The compute infrastructure that pulls, transforms, and pushes the data in these data pipelines is called an Integration Runtime (IR). To make life easy Azure provides a regional IR by default, including an IP range on which these machines are running. Although convenient, this setup presented a serious security issue.
The third-party solution did not expose it’s data via an API, but via access to their managed databases. One of their security measures was IP whitelisting. It’s possible to whitelist the regional IR IP range, but that would cause a serious security issue, since anyone with an Azure account can use the same regional IR.
As a solution, with the guidance of an experienced Cloud Architect, I build a general, scalable, and cost-efficient solution to this integration challenge, which consists of the following five steps:
- Build a Dockerfile with a Windows server base OS image, a self-hosted integration runtime, and Java runtime.
- Host the Dockerfile in an Azure Container Registry.
- Deploy an Azure Data Factory instance and copy the unique identifier.
- Deploy the Docker container with Azure Container Instances and link the self-hosted integration runtime to the Azure Data Factory instance.
- Retrieve the public IP address of the Docker container and provide it to the third-party for whitelisting.
The solution was wrapped as Infrastructure-as-Code with Bicep and PowerShell, and made available in Azure DevOps for other teams facing the same challenge.